목차
Python 메모리 관리 기법
- 프로세스의 메모리 안의 힙 영역에서는 메모리 공간을 할당하면 언젠가는 해당 공간을 반환해주어야합니다. C/C++은 메모리를 직접 해제해줘야하지만 Python이나 Java의 경우 Garbage collection 방식을 적용하여 자동으로 쓰레기 메모리들을 정리해줍니다.
- 참고 : 파이썬의 장점
- 컴파일 안해도 됨.
- 메모리 관리 안해도 됨. (Garbage collection)
- 간단하다.
- 참고 : 파이썬의 장점
- Python의 Garbage collection 방식에는 참조 카운팅(Reference counting)방식과 Garbage Collector(GC) 방식이 있습니다. 이를 이용하여 메모리 관리를 진행합니다.
참조 카운팅(Reference counting)
- 참조 카운팅방식은 객체에 대한 참조가 0이 되었을때, 그 객체를 메모리에서 지워줍니다.
- 참조 카운트를 확인하는 방법은 sys.getrefcount를 이용하면 됩니다.
- 참조 카운팅방식을 통해 메모리 관리하는 예시를 통해 참조 카운팅을 이해해보겠습니다.
- 먼저 Link 클래스를 만든 뒤 a, b 객체를 생성해보도록 하겠습니다.
-
import sys class Link: def __init__(self, next_link=None): self.next_link = next_link a = Link() b = Link() print(sys.getrefcount(a) - 1) print(sys.getrefcount(b) - 1) --> 1 1- 여기서 a와 b는 1씩 감소를 해주는 이유는 sys.getrefcount를 실행할때 참조 카운트가 1씩 증가하기 때문입니다.

- 위 그림처럼 a와 b가 생성한 객체의 참조 카운트는 1이 될것입니다.
-
- 여기서 a객체의 next_link를 b로 지정해보도록 하겠습니다.
-
import sys class Link: def __init__(self, next_link=None): self.next_link = next_link a = Link() b = Link() a.next_link = b print(sys.getrefcount(a) - 1) print(sys.getrefcount(b) - 1) print(sys.getrefcount(a.next_link) - 1) --> 1 2 2 
- a.next_link가 b가 가르키는 객체를 가르키므로 b가 가르키는 객체의 카운트는 2로 증가할 것입니다.
- a.next_link도 b가 가르키는 객체를 가르키기때문에 sys.getrefcount(b)를 하거나 sys.getrefcount(a.next_link)를 해도 동일한 결과가 나올 것입니다. (b와 a.next_link가 동일한 객체를 가르키기때문)
-
- 이제 여기서 두 가지 상황을 나눠서 생각해보도록 하겠습니다. 한번은 a를 삭제하고, 한번은 b를 삭제해보도록 하겠습니다.
- a를 삭제할 경우 (del a를 통해 삭제해도 되지만, None을 지정하는 방식을 통해 삭제해보았습니다.)
-
import sys class Link: def __init__(self, next_link=None): self.next_link = next_link a = Link() b = Link() a.next_link = b a = None print(sys.getrefcount(a) - 1) print(sys.getrefcount(b) - 1) --> 3802 1 

- a가 사라져서 a가 가르키던 해당 객체의 참조 카운트가 1이 감소하게 될것입니다. 결국 해당 객체에 대한 참조 카운트는 0이 되어 해당 Link는 사라지게 됩니다.
- 이것이 사라지면서 사라진 Link가 가르키던 b가 가르키는 객체에 대한 참조 카운트도 1이 감소하게 됩니다.
-
- b를 삭제할 경우
-
import sys class Link: def __init__(self, next_link=None): self.next_link = next_link a = Link() b = Link() a.next_link = b b = None print(sys.getrefcount(a) - 1) print(sys.getrefcount(b) - 1) print(sys.getrefcount(a.next_link)-1) --> 1 3799 1 
- b가 사라졌지만 b가 지정하던 Link()는 a.next_link를 통해 지정되어져 있어서 해당 Link()는 메모리에서 살아있게 됩니다.
- (sys.getrefcount(a.next_link)가 기존에 b가 가르키던 Link() 입니다.)
-
- a를 삭제할 경우 (del a를 통해 삭제해도 되지만, None을 지정하는 방식을 통해 삭제해보았습니다.)
- 이와 같이 특정 객체나 값을 가르키던 변수나 객체가 사라지게 된다면 특정 객체나 값에 대한 참조 카운트가 1씩 감소하게 됩니다. 이러다가 만약 0이 될 경우 해당 데이터는 메모리에서 삭제되게 됩니다. 이러한 방법을 참조 카운팅 방법이라고 합니다.
- 먼저 Link 클래스를 만든 뒤 a, b 객체를 생성해보도록 하겠습니다.
- 참조 카운팅 방식의 한계
- 참조 카운팅은 대부분의 경우에서 효율적으로 메모리에서 데이터를 제거할 수 있지만, 순환 참조가 있는 경우에는 메모리에서 제거할 수 없습니다. 순환 참조는 서로가 서로를 가르켜 결국에는 참조 카운트가 0이 될 수 없는 상황을 말합니다.
- 순환 참조 예시
- a와 b로 객체를 지정하고, 해당 객체의 next_link를 서로 지정하게 해줍니다.
-
import sys class Link: def __init__(self, next_link=None): self.next_link = next_link a = Link() b = Link() a.next_link = b b.next_link = a print(sys.getrefcount(a) - 1) print(sys.getrefcount(b) - 1) print(sys.getrefcount(a.next_link) - 1) # b가 가르치는 객체 print(sys.getrefcount(b.next_link) - 1) # a가 가르치는 객체 --> 2 2 2 2 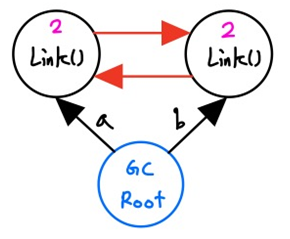
-
- 여기서 a와 b를 둘다 삭제해버리면 어떻게 될까요?
-
import sys class Link: def __init__(self, next_link=None): self.next_link = next_link a = Link() b = Link() a.next_link = b b.next_link = a a = None b = None 
- a와 b가 다른 값을 지정하므로 기존 객체들에 대한 참조 카운트 값은 1 씩 줄어들 것입니다. 하지만 그 객체들은 서로를 가르키고 있어 참조 카운트가 여전히 1입니다. a와 b가 둘다 사라져 이 객체에는 더 이상 접근할 방법도 없어 참조 카운팅 방식을 통해 메모리에서 제거할 방법은 없습니다.
-
- a와 b로 객체를 지정하고, 해당 객체의 next_link를 서로 지정하게 해줍니다.
- 이처럼 순환 참조 상황은 참조 카운팅 만으로는 해당 데이터를 메모리에서 제거할 수 없습니다. 따라서 Garbage Collector(GC)라는 방식이 도입되게 되었습니다.
Garbage Collector
- 참조 카운팅 방식에서 해결하지 못한 순환 참조를 해결하기 위한 도입된 것이 Garbage Collector(GC)입니다.
- 파이썬은 gc 모듈을 통해 Garbage Collector를 직접 제어할 수 있습니다.
- gc 모듈은 오로지 순환 참조를 탐지하고 해결하기 위해 존재합니다.
- Garbage Collector는 관리하는 객체들
- 순환 참조가 발생할 가능성이 있는 컨테이너 타입의 객체들(예 : 리스트, 딕셔너리, 클래스 인스턴스 등)에 대해서만 관여합니다.
- 단순한 값들(예 : 정수, 부동소수점 수, 문자열 등)은 순환 참조의 위험이 없기 때문에 가비지 컬렉터의 직접적인 관리 대상에서 제외됩니다.
- Garbage Collector는 순환 참조가 발생할 수 있는 컨테이너 타입의 객체들이 생성될때마다 기록해두고, 그렇게 기록된 객체의 수가 특정 threshold 값을 넘어서게 되면 순환 참조 여부를 파악하고 순환 참조가 발생한 객체들을 메모리에서 제거해줍니다.
- GC는 3가지 세대의 공간을 두어 빈번하게 메모리정리를 시행하는 것을 방지해주었습니다.
- 0세대, 1세대, 2세대
- 각 세대의 기본 threshold 값은 700, 10, 10 입니다.
- 가장 먼저 0세대 공간에 컨테이너 타입의 객체들이 생성될때마다 해당 값을 1씩 늘려줍니다.
- 그 후 0세대의 threshold 값을 넘어선 700개의 객체들이 생성되었다면, 해당 객체들에 대해서 순환 참조가 발생했는지 여부를 검사합니다. 그 중 순환 참조가 발생한 객체들은 0세대 공간에서도 제거해주고, 메모리 공간에서도 제거해줍니다. 순환 참조가 발생하지 않은 객체들은 1세대 공간으로 옮겨줍니다. (그리고 나서 1세대의 count값을 1만큼 올려줍니다.)
- 옮겨주는 이유는 아직까지는 순환 참조가 발생하지는 않았지만, 추후에 나중에 더많은 객체가 생성되다보면 순환 참조가 발생할수 있기 때문입니다.
- 이런식으로 반복하여 0세대 공간에서 검사가 1세대 threshold만큼 이루어지게 되면 그때 1세대 공간에 대해서 검사가 진행됩니다. 마찬가지로 이 역시 다시 한번 해당 객체들에 대해 순환 참조가 발생했는지 검사합니다. 마찬가지로 순환참조가 발생한 객체들은 1세대 공간과 메모리에서 제거해주고, 순환 참조가 발생하지 않은 객체들은 2세대 공간으로 옮겨줍니다. 그리고 나서 2세대 count 값을 1만큼 올려줍니다.
- 마지막 2세대 역시 이와 같은 방법으로 계속해서 검사를 진행하게 될것입니다.
- 즉, 0세대는 threshold[0]만큼 객체가 쌓이면 진행되고, 1세대는 약 threshold[0] * threshold[1] 만에 검사 진행. 2세대는 threshold[0] * threshold[1] * threshold[2] 만에 검사가 진행됩니다.
- 즉 기본값이면 700, 7000, 70000
- 이처럼 3가지 세대를 두어 0세대를 한번 통과한 객체들은 바로 빈번하게 검사하기 보다는 다음 세대에 넣어두어 검사 주기를 줄여줍니다. (한 번 순환참조가 발생하지 않았던 객체들은 순환 참조가 발생하지 않을 가능성이 크기 때문입니다.)
- GC는 3가지 세대의 공간을 두어 빈번하게 메모리정리를 시행하는 것을 방지해주었습니다.
- 그럼 Garbage Collector가 어떤 방식으로 순환참조가 있는지 체크를 진행할까요?
- 마킹 단계(Marking Phase)
- 모든 객체는 초기에 "미접근(unreached)" 상태로 마킹됩니다.
- 가비지 컬렉터는 루트 집합(root set)에서 시작하여 접근 가능한 객체를 추적합니다. 루트 집합에는 글로벌 변수, 스택 프레임 내의 지역 변수 등이 포함됩니다.
- 접근 가능한 객체를 발견할 때마다, 해당 객체와 그 객체가 참조하는 모든 객체를 "접근 가능(reachable)"으로 마킹합니다. 이 과정은 재귀적으로 반복됩니다.
- 스위핑 단계(Sweeping Phase)
- 마킹 단계 이후, "미접근" 상태로 남아있는 객체들은 순환 참조를 포함하는 객체들입니다. 이 객체들은 더 이상 프로그램 코드에서 접근할 수 없는 상태이지만, 서로를 참조함으로써 참조 카운트가 0이 되지 않습니다.
- 가비지 컬렉터는 이러한 "미접근" 객체들을 메모리에서 해제합니다.
- 마킹과 스위핑 단계를 거쳐 참조 카운트가 0이 되지 않아 메모리에서 살아 있지만 접근 가능하지 않은 객체들은 메모리에서 삭제시켜주는 것입니다.
- 이러한 작업은 프로그램을 멈추고 진행해야하기때문 생각보다 시간이 많이 소요될 수 있습니다.
- 마킹 단계(Marking Phase)
- 순환 참조를 발생시키지 않을 자신이 있다면, Garbage Collector를 비활성화하여 시간을 절약할 수 있습니다.
- 인스타그램의 경우 Garbage Collector를 비활성화하여 성능을 10%가량 향상시켰습니다.
- 비활성화 시키는 방법에는 아래 코드를 실행하면 됩니다.
-
gc.set_threshold(0, 0, 0)
-
- 순환참조가 없는 예시
- 순환참조가 없고, garbage collector를 사용한 경우
-
import os import gc import time import random import psutil def report_process_mem() -> int: process = psutil.Process(os.getpid()) mb = process.memory_info().rss / 1024 / 1024 print(f"Total memory used: {mb:,.2f} MB.") return mb class Item: def __init__(self, x, y): self.x = x self.y = y def create_some_items(count): items = [] for _ in range(0, count): items.append(Item(random.random(), [{} for _ in range(20)])) return items count = 1000 times = 100 start_time = time.time() print(gc.get_count()) lists_of_items = [] for _ in range(times): lists_of_items.append(create_some_items(count)) print(gc.get_count()) end_time = time.time() print("걸린 시간 : ", end_time - start_time) report_process_mem() --> (174, 10, 1) (173, 7, 51) 걸린 시간 : 0.2650315761566162 Total memory used: 175.35 MB.
-
- 순환참조가 없고, garbage collector를 사용하지 않은 경우
-
import os import gc import time import random import psutil def report_process_mem() -> int: process = psutil.Process(os.getpid()) mb = process.memory_info().rss / 1024 / 1024 print(f"Total memory used: {mb:,.2f} MB.") return mb class Item: def __init__(self, x, y): self.x = x self.y = y def create_some_items(count): items = [] for _ in range(0, count): items.append(Item(random.random(), [{} for _ in range(20)])) return items gc.set_threshold(0, 0, 0) count = 1000 times = 100 start_time = time.time() print(gc.get_count()) lists_of_items = [] for _ in range(times): lists_of_items.append(create_some_items(count)) print(gc.get_count()) end_time = time.time() print("걸린 시간 : ", end_time - start_time) report_process_mem() --> (174, 10, 1) (2200264, 10, 1) 걸린 시간 : 0.11102986335754395 Total memory used: 175.42 MB. - garbage collector를 사용했을때보다 시간이 2~3배 빨라지는 것을 확인할 수 있습니다. 또한 순환 참조가 없기때문에 낭비되는 메모리가 없으므로 전체 메모리 사용량은 동일합니다.
-
- 순환참조가 없고, garbage collector를 사용한 경우
- 순환참조가 있는 예시
- 순환참조가 있고, garbage collector를 사용한 경우
-
import os import gc import time import psutil def report_process_mem() -> int: process = psutil.Process(os.getpid()) mb = process.memory_info().rss / 1024 / 1024 print(f"Total memory used: {mb:,.2f} MB.") return mb class Item: def __init__(self): self.next = None start_time = time.time() print(gc.get_count()) for _ in range(1000000): a = Item() b = Item() a.next = b b.next = a print(gc.get_count()) end_time = time.time() print("걸린 시간 : ", end_time - start_time) report_process_mem() --> (214, 10, 1) (261, 6, 228) 걸린 시간 : 0.3150789737701416 Total memory used: 15.12 MB.
-
- 순환참조가 있고, garbage collector를 사용하지 않은 경우
-
import os import gc import time import psutil def report_process_mem() -> int: process = psutil.Process(os.getpid()) mb = process.memory_info().rss / 1024 / 1024 print(f"Total memory used: {mb:,.2f} MB.") return mb class Item: def __init__(self): self.next = None # GC 사용하지 않기 gc.set_threshold(0, 0, 0) start_time = time.time() print(gc.get_count()) for _ in range(1000000): a = Item() b = Item() a.next = b b.next = a print(gc.get_count()) end_time = time.time() print("걸린 시간 : ", end_time - start_time) report_process_mem() --> (214, 10, 1) (2000214, 10, 1) 걸린 시간 : 0.25305843353271484 Total memory used: 198.76 MB. - 순환참조가 있을 경우에는 GC를 사용했을때와 사용하지 않았을 경우 메모리 차이가 약 10배이상 납니다.
-
- 위 코드가 순환참조로 인해 메모리가 낭비되는 이유는 아래와 같습니다.
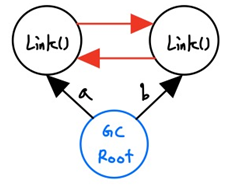

- a,b가 다른 객체를 지정하면서 기존의 Link()들은 더이상 접근할 수 없는 형태로 메모리에 남아있게 됩니다.

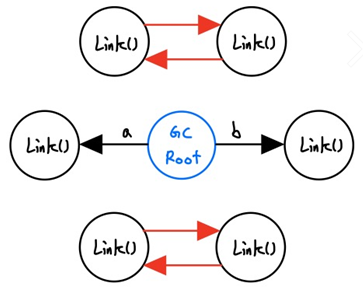
- 결국 이런식으로 계속 진행하다보면 순환참조로 인해 메모리에서 접근할수 없는 (즉 참조카운트는 1이상이지만 접근할수 없는경우) 경우가 엄청나게 많이 생기게됩니다.
- 순환참조가 있고, garbage collector를 사용한 경우
- 정리
- 순환참조를 안생기게 할 자신이 있다면 gc.set_threshold(0, 0, 0)을 통해 성능향상을 기대할 수 있습니다.
- 하지만 순환참조가 생기는데 GC를 비활성화하게 된다면 심각한 메모리 낭비현상이 발생할 수 있습니다.
참고
'Language > Python' 카테고리의 다른 글
| __init__.py 역할 (import 할 시에 주의사항) (1) | 2023.12.20 |
|---|
