목차
Key-value Database
- 데이터 저장 방식
- 데이터를 key-value 형태로 저장하는 데이터베이스

- 너무 간단해서 실용성이 없습니다. (서브용 DB로 많이 사용)
- DBMS 예시
- redis

- 특수한 기능을 가진 key-value database (redis는 key-value database이지만 많이 사용됩니다.)
- 데이터를 하드디스크에 저장하지 않고, 1차적으로 ram(메모리)에 저장합니다.
- ram(메모리)이 하드디스크보다 훨씬 빠르기 때문
- redis 활용 방식
- main DB 하나를 두고, 거기서 자주 사용되는 데이터를 redis에 추가로 복사해 둡니다.
- 자주 사용되는 데이터를 달라고 할 경우 메인 DB가 아닌, redis에서 꺼내서 보여줍니다.
- 하드디스크가 아닌 ram(메모리)에서 꺼내오기 때문에 되게 빠른 서비스를 만들 수 있습니다.

- redis
Relational Database(관계형 데이터베이스)
- 데이터 저장 방식
- table(표)을 하나 만들고 table(표) 위에다가 어떤 데이터를 저장할지 이름을 지정해 줍니다. 그 후 하나의 행마다 데이터를 보관할 수 있습니다.

- 이러한 형식을 갖춘 엑셀도 관계형 데이터베이스라고 할 수 있습니다.
- DBMS 예시
- 대량의 데이터를 저장하려면 Oracle, MySQL, PostgreSQL 등 이런 DBMS를 사용하는 경우가 많습니다.
- DBMS(Database Management System)
- 데이터베이스 조작을 쉽게 도와주는 프로그램
- 데이터입출력도 쉬워짐
- DB 접속 계정 발급 가능
- 백업도 쉬움
- DBMS(Database Management System)

- 대량의 데이터를 저장하려면 Oracle, MySQL, PostgreSQL 등 이런 DBMS를 사용하는 경우가 많습니다.
- 특징
- Relational Database(관계형 DB)에 데이터를 저장하고 싶다면 SQL(Structured Query Lnaguage)이라는 문법을 사용해야 합니다.
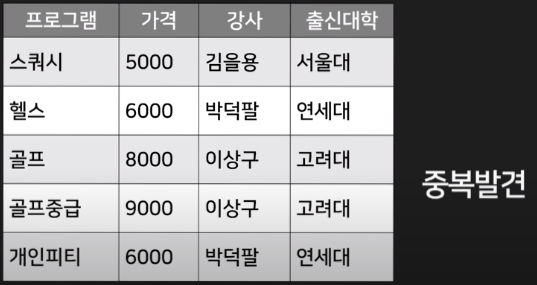
- 정규화
- 관계형 DB를 사용할 때는 정규화가 반드시 중요합니다.
- 정규화를 간단하게 말하면 데이터가 중복된다고 하면은 여러 테이블로 분리시켜 주는 것입니다.
- 정규화의 단점은 데이터 출력 문법이 길고 복잡해지게 됩니다.
- ACID Transaction 기능
- 돈거래 같은 중요한 기능을 구현하고 싶을 때 안전하게 구현할 수 있습니다.
- 따라서 입출력 속도보다 데이터 정확도가 매우 중요하다 할 경우 일반적으로 관계형 DB를 사용하는 경우가 많습니다.

Graph Database
- 데이터 저장 방식
- 노드를 만들고 노드 안에 데이터들을 저장합니다.
- 노드끼리의 관계가 어떤 관계인지 기록해 둘 수 있습니다.

- 관계가 중요할 때 사용합니다.
- DBMS 예시

- neo4j가 가장 유명
- 특징
- Graph Database에서 데이터를 입출력할 때는 Graph Query Language를 사용합니다.
- 자료 간의 관계 방향 같은 걸 중점적으로 저장하고 싶을 때 사용하면 됩니다.
- 비행기 노선, SNS 친구 관계, 추천 서비스 등..
Document Database
- 데이터 저장 방식
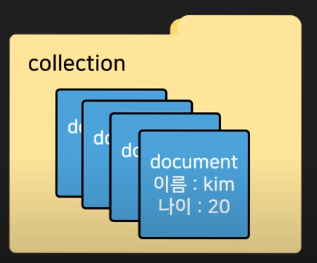
- collection이라는 폴더 하나를 만들고 그 안에다가 document라고 부르는 하나의 파일들을 만들어서 데이터를 저장합니다. 파일 안에는 json 형태로 데이터를 저장할 수 있습니다.
- 관계형 데이터베이스에 비해 자유로운 데이터베이스입니다.
- collection이라는 폴더 하나를 만들고 그 안에다가 document라고 부르는 하나의 파일들을 만들어서 데이터를 저장합니다. 파일 안에는 json 형태로 데이터를 저장할 수 있습니다.
- DBMS 예시
- 특징
- 관계형 DB와 다르게 어떤 데이터를 저장할지 미리 정해 놓을 필요가 없습니다. (관계형 DB보다 훨씬 자유로움)
- 기존에 없던 키값을 새롭게 추가시켜 넣어주어도 에러가 발생하지 않습니다. (아래 예시를 보면 연락처라는 새로운 키값을 추가시켜주더라도 에러가 발생하지 않습니다.)

- 가장 큰 특징은 데이터의 중복 제거를 하지 않습니다. (즉, 정규화를 하지 않습니다.)
- 따라서 데이터 입출력 문법들이 훨씬 간단한 편입니다.
- 대부분 분산을 염두에 두고 만들어진 데이터베이스이기 때문에 데이터베이스를 분산시키는 것이 쉽습니다.
- 단, 분산해 놓으면 DB 간에 정확도(일관성)가 떨어질 수 있습니다.
- 관계형 DB와 다르게 어떤 데이터를 저장할지 미리 정해 놓을 필요가 없습니다. (관계형 DB보다 훨씬 자유로움)

Column-family Database
- 데이터 저장 방식
- 관계형 DB같이 표 형식으로 데이터를 저장하고 싶은데 조금 유연하게 사용하고 싶다면 Column-family Database를 사용하면 됩니다.
- 똑같이 table을 하나 만들고 row를 생성한 뒤에 거기에다가 자유롭게 컬럼을 만들어서 데이터를 기입하는 식으로 자료를 저장합니다.

- DBMS 예시
- 특징
- Column-family Database에 데이터를 입출력하려면 SQL이 아니라 자기들이 만든 언어를 사용해야 합니다.
- 카산드라의 경우 CQL(Cassandra Query Language) 사용
- 정규화를 진행하지 않습니다. (중복 제거를 하지 않습니다.)
- 복제, 분산 처리를 잘합니다. 따라서 많은 입출력을 감당해야 된다고 하면 Column-family Database를 사용하는 경우들이 있습니다.
- 하지만 복제, 분산을 하게 되면 데이터 일관성이 부족해진다는 단점이 있습니다.
- 데이터를 저장할 때 시간 기록을 쉽게 해주는 기능이 있어 시계열 데이터 저장하고 분석할 때 Column-family Database를 사용하는 경우가 있습니다.

- (넷플릭스에서 시청기록 이걸로 분석)
- Column-family Database에 데이터를 입출력하려면 SQL이 아니라 자기들이 만든 언어를 사용해야 합니다.

Search engine
- 데이터 저장 방식
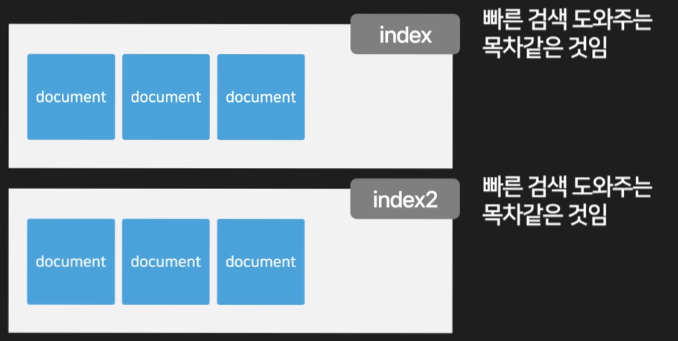
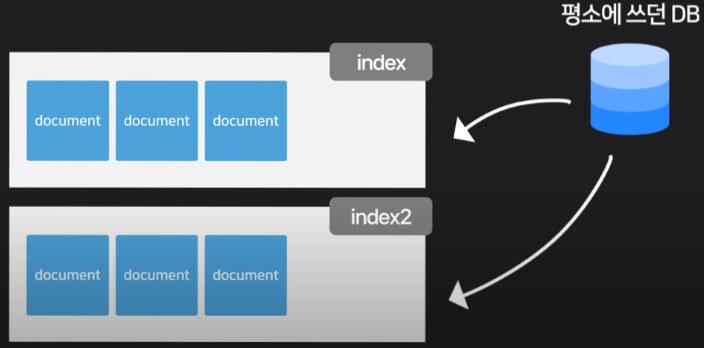
- 검색용 인덱스를 보관하기 위한 데이터베이스(index 보관에 특화)
- 인덱스란 데이터 검색을 빠르게 할 수 있게 도와주는 색인, 목차 같은 것입니다.
- 평소에 사용하던 기존 DB에서 데이터를 뽑아서 여기에다 입력을 하면 인덱스를 생성한 뒤 보관해 줍니다. 그래서 이제 검색 요청이 들어오면 인덱스를 이용해 자료 검색을 도와줍니다.
- 검색이 중요한 사이트를 만들 때 이것을 가져다가 사용하는 경우가 많습니다.
- 검색용 인덱스를 보관하기 위한 데이터베이스(index 보관에 특화)
- DBMS 예시

정리
- 일반적으로는 Relational Database(관계형 데이터베이스) / Document Database 중에 하나 골라서 사용합니다.
- 정확도와 일관성이 중요하면 Relational Database가 일반적
- 입출력이 매우 많으면 Document Database가 일반적
출처
'Database > ETC' 카테고리의 다른 글
| csv 파일 DBeaver에 불러오기 (0) | 2024.02.28 |
|---|---|
| DBeaver 설치 (0) | 2024.02.27 |

